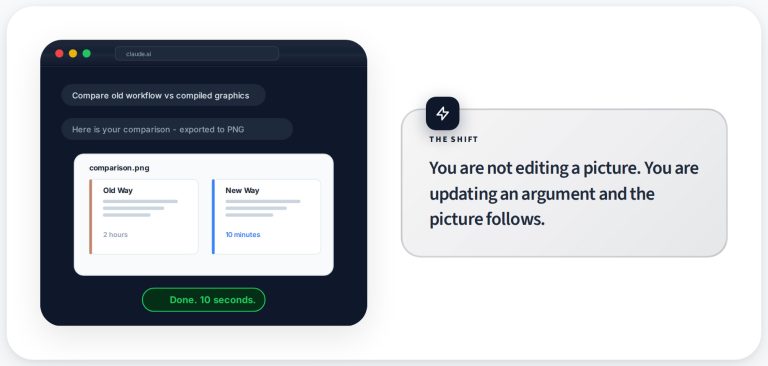
Your team can ship 10x more, but your judgement still doesn’t scale.
“Why can’t we move faster?” is the question haunting product teams right now. The usual suspects: tech debt, decision debt, not enough hands. “Not enough resources” or “too many problems, pick one.”
One root cause is cycle time—the need to keep changes atomic, low-risk, and decoupled. Take a small front-end fix. You move through problem identification, investigation, implementation, review, testing, revision, release.
Multiply that by a backlog of “small improvements,” and most of the week disappears into mechanical work. In that world, execution was expensive. Prioritization mattered, but capacity was the visible constraint.
That assumption is breaking. With bounded agent workflows, I can run small implementation tasks in parallel using explicit “skills” and scoped “subagents.” These bots draft changes, generate tests, produce PR notes, and surface risks for review.
They are not magical “Sorcerer’s Apprentice” bots. They do what you tell them—and maybe a bit more. They make mistakes, but they are reliable enough that execution cost is dropping fast.
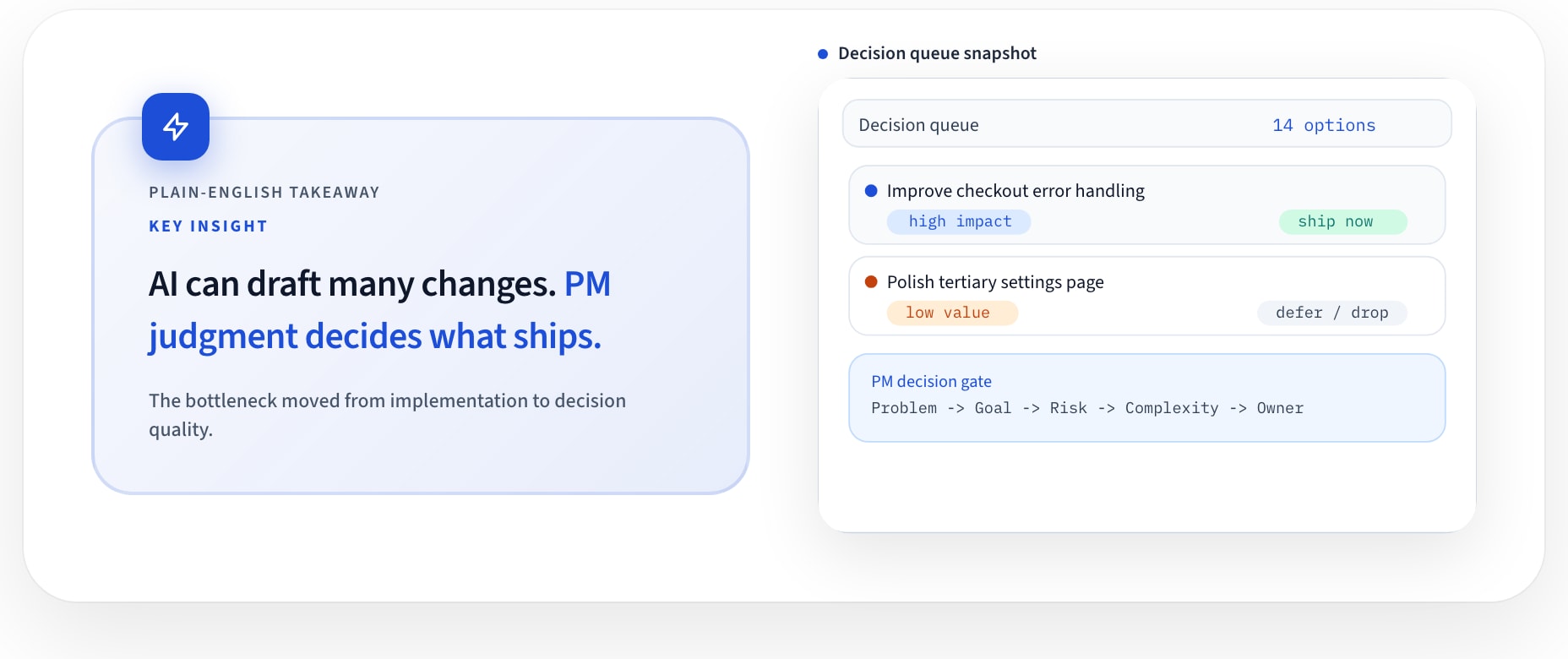
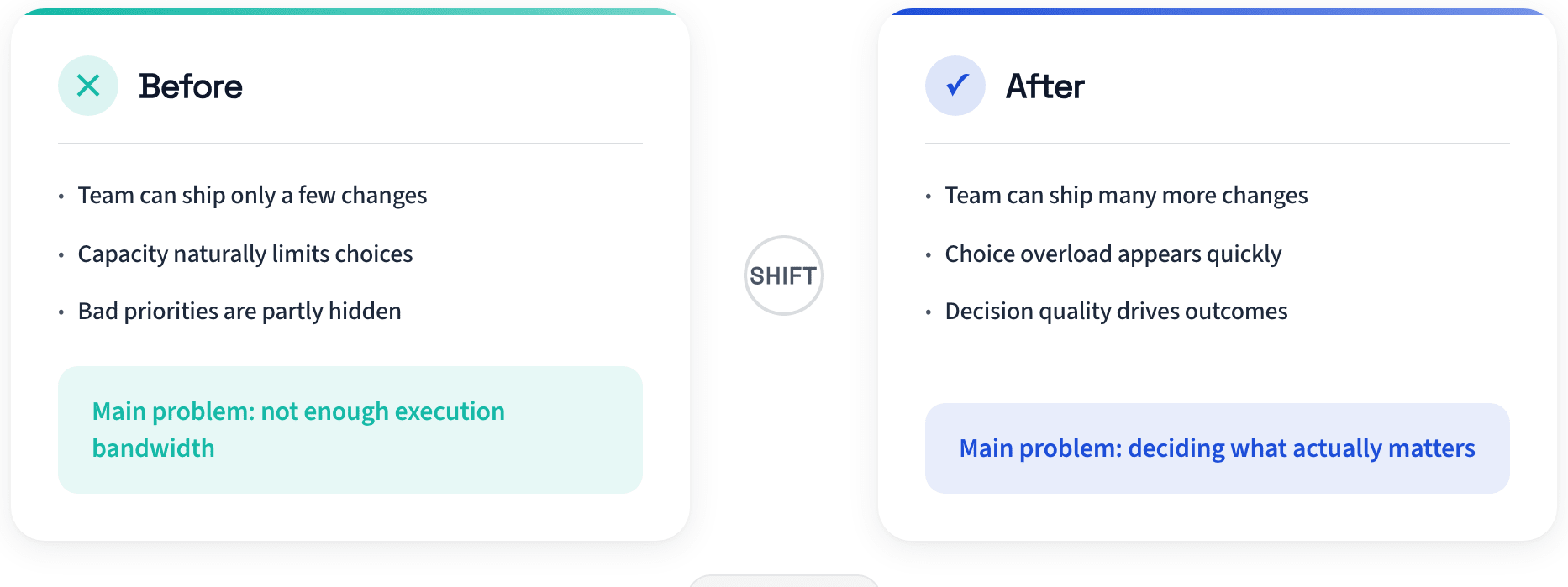
When execution becomes cheap, weak judgment gets exposed.
The bottleneck moved upstream
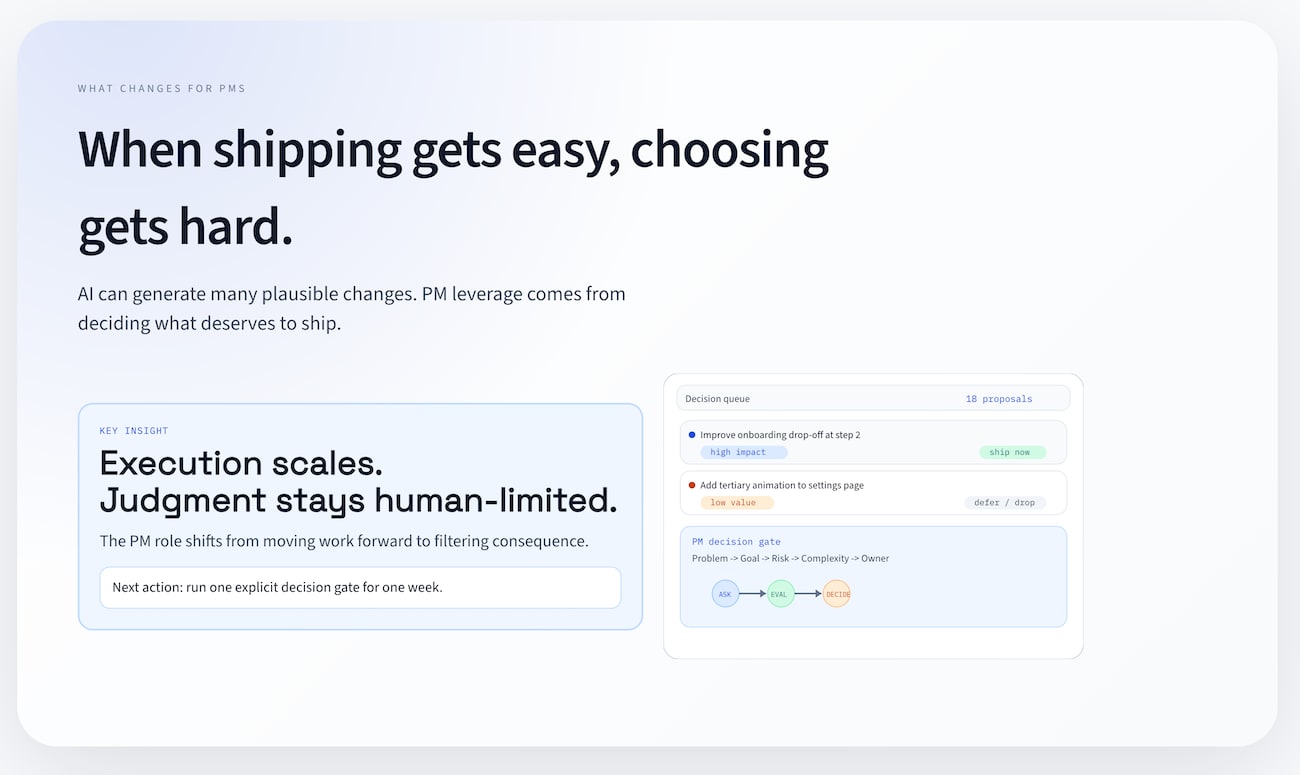
Software is not limited by typing speed, or even by agents filling in software Mad Libs on your behalf. Software is limited by decision quality and second-order effects.
-
What should exist at all?
-
What failure modes are we introducing?
-
What complexity are we normalizing?
-
What future roadmap options are we quietly closing?
When implementation is expensive, bad prioritization hides behind scarcity. You cannot approve everything.
When execution gets cheap, that buffer disappears.
If your team can generate ten viable changes by noon, the problem is no longer “Can we build this?” It is “Can we choose well enough to avoid compounding noise?”
That is a different operating environment. It rewards a different PM posture.
A concrete example of where teams drift
Here’s what I worry about in a world of agent-enabled teams, and what we need to guard against.
By Tuesday, there is a queue of fourteen plausible UI improvements:
-
better inline validation copy
-
cleaner error states
-
accessibility upgrades in shared components
-
minor performance fixes
-
onboarding friction reducers
-
small design consistency cleanup
Every item is reasonable. None is catastrophic. Most are easy to justify in isolation.
The PM approves ten because they’re low effort and execution is now cheap.
Two weeks later, the team has mixed outcomes:
-
some local UX wins
-
slightly lower support volume in one path
-
higher review overhead because PR volume exploded
-
more component divergence than before
-
roadmap work slowed by integration and cleanup noise
No single decision was “bad,” but the aggregate customer experience didn’t get better. Failure now looks like fast accumulation of acceptable changes that dilute the product.
Cheap execution does not increase your weekly supply of high-quality decisions.
Why this is now a PM leverage question
When teams adopt agents, execution mechanics can be partially automated. Throughput coordination becomes less differentiating. Decision governance becomes more valuable.
That does not mean PMs need to become full-time engineers.
It means PMs need technical boundary fluency: enough to interrogate consequence before approving work from agent pipelines.
When I review agent output, I want clear answers to:
-
What exact files and surfaces are touched?
-
What is the rollback path if this creates regressions?
-
What class of bug is most likely here?
-
What coupling or complexity is being added?
-
What signal will tell us this was actually worth shipping?
If those answers are vague, we are not exercising judgment. We are delegating judgment to momentum. Momentum does not protect system quality.
The operating model that actually works
The teams getting real leverage are not using unconstrained autonomy. They run constrained execution with explicit human decision gates.
In practice:
-
Constrain intake Each task gets a tight scope and explicit out-of-bounds rules.
-
Run specialized subagents Use targeted skills for bounded work units (e.g., UI validation pass, accessibility patch, test generation), not broad “fix everything” prompts.
-
Enforce an output contract Each subagent must return: diff summary, assumptions, risk notes, tests, and rollback plan.
-
Gate through PR review A PR is reviewable evidence, not automatic merge authority. PM + engineering review consequence, not just effort.
-
Validate post-ship signal Changes without observable success/failure criteria are parked or rejected.
The key principle: approval is tied to consequence, not implementation cost.
Here is the compact checklist I use before approving agent-generated work:
PM_DECISION_GATE
1) Scope check: Is this exactly in-bounds?
2) Impact check: Which objective does this move?
3) Risk check: What breaks, and how do we roll back?
4) Complexity check: Did we simplify or add surface area?
5) Evidence check: What metric/event confirms value?
6) Ownership check: Who owns outcome after merge?
If a change cannot pass this gate quickly, speed is the wrong goal.
A potential weekly cadence:
-
Monday: define bounded agent tasks tied to one product objective
-
Midweek: run subagent outputs through PR gates with explicit risk calls
-
Friday: review shipped items against evidence criteria and mark regret decisions
The capability challenge is real, but learnable
PMs who stay at ticket choreography level will lose leverage in agentic teams.
That is not because they are less smart. The market is revaluing what PM work matters under execution abundance.
The upside: this capability is trainable faster than people think.
A practical path:
-
sit in PR gates for agent-generated changes and ask one consequence question every time
-
keep a monthly “decision regret” log of shipped work you would now reject
-
require rollback + observability notes for every non-trivial change
-
build deep fluency in one layer of the stack where your product risk is concentrated
You do not need to write production code daily. You need to reason clearly at decision boundaries.
PMs who can do that become force multipliers. They turn execution abundance into focused product progress instead of complexity debt.
The optimistic version of this shift
This is not a story about protecting PM territory from automation.
It is a chance to remove mechanical drag and reinvest attention into higher-order judgment:
-
sharper sequencing
-
cleaner product boundaries
-
better tradeoff quality
-
less accidental complexity
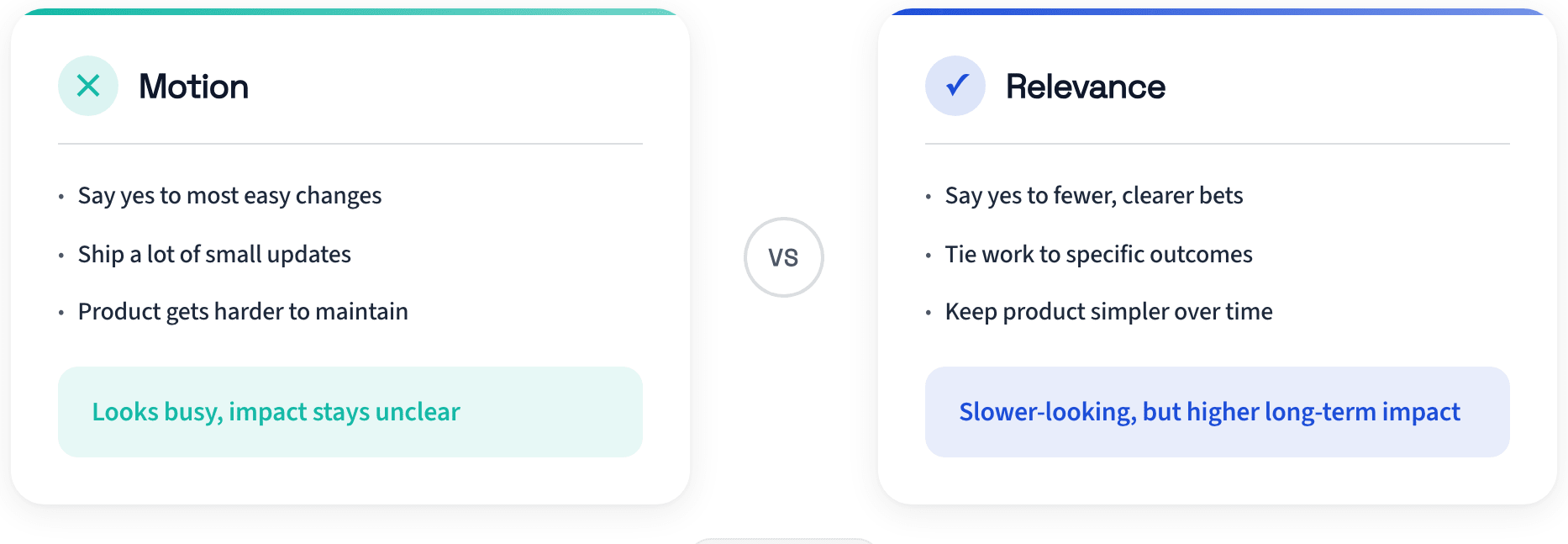
Engineers can spend more cycles on architecture and reliability. PMs can spend more cycles on decision quality and coherence. When execution is cheap, relevance is the discipline.
Where PMs usually get this wrong first
The first mistake is treating agent throughput as automatically strategic throughput. But more completed work can still mean less progress if the work is weakly connected to outcomes.
The second mistake is approving changes because review friction is lower. Low-friction approval often hides high downstream cost—more exceptions, more implicit coupling, more “tiny” one-off logic that future teams inherit.
The third mistake is lack of ownership when changes need to be committed and approved. If a PM approves, an engineer merges, and no one clearly owns post-ship consequence, quality will drift no matter how good the tools are.
These are process failures, not model failures.
If teams blame the agent for every bad outcome, they avoid the harder fix: raising decision standards, clarifying ownership, and making consequence visible at approval time.
The new default
In an agentic environment, “yes” is no longer a neutral choice.
Every approval changes the system. Every added branch increases future cost. Every local win competes with strategic focus.
The default needs to shift:
Approve less. Approve better.
-
Keep autonomy bounded.
-
Keep gates explicit.
-
Keep decision rights close to consequence.
-
Keep PM attention on what compounds.
Execution can now scale in parallel.
Judgment still scales one careful decision at a time. That is not a weakness in the system. It is the center of the PM job now.
If this resonates, the practical question is simple: where in your current workflow are you still rewarding motion over relevance?

What’s the takeaway? As a PM, you need to be pushing and approving the highest-leverage items. Be careful what you decide to build and approve. It can solve today’s apparent problem but create tomorrow’s backlog if you’re not careful.