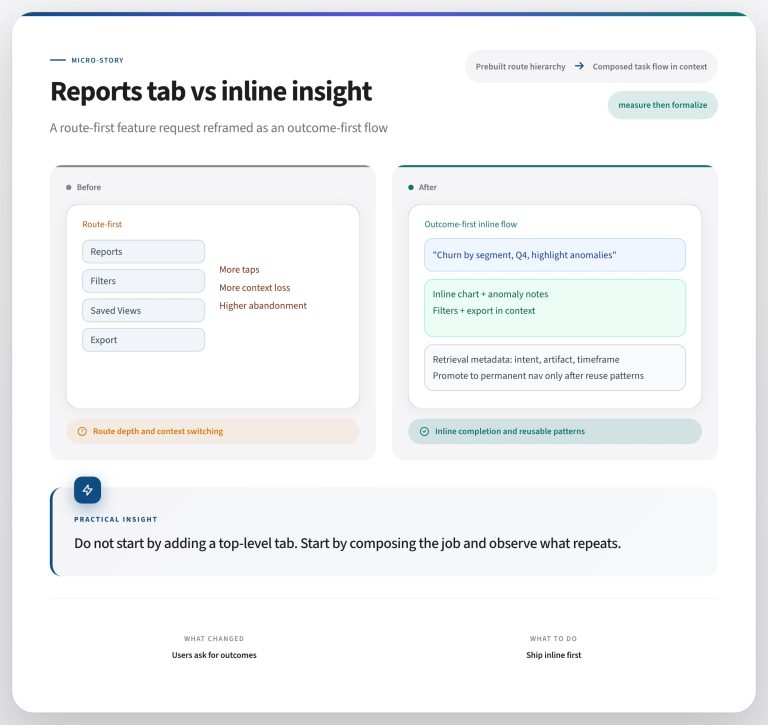
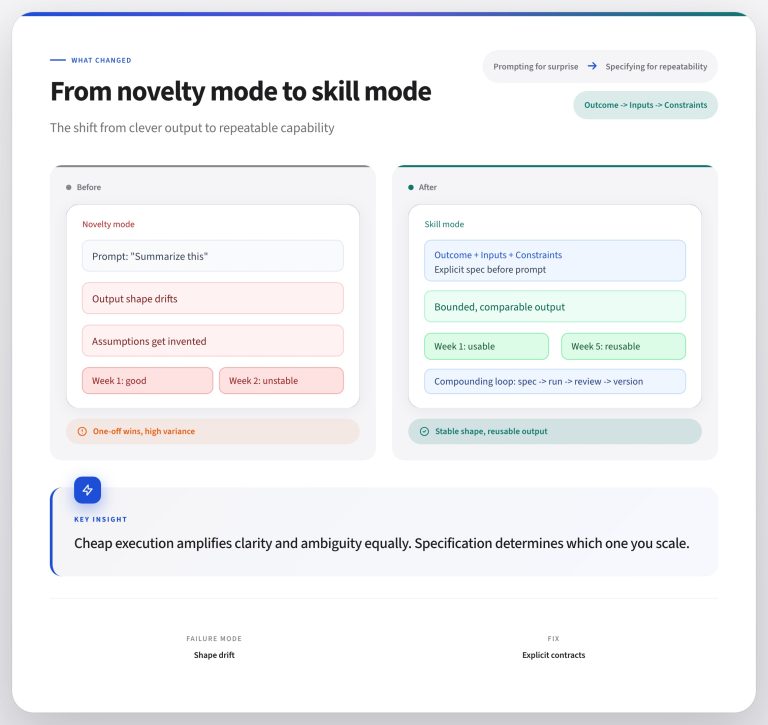
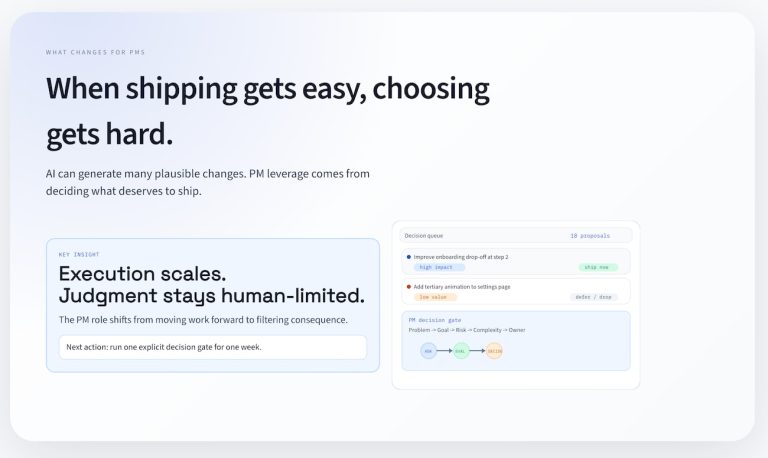
Trust can be a fragile thing, especially when it comes to metrics the team looks at every day. The balance of items that create the end product on a dashboard might be easily upset. But the team measures progress on being able to measure the same item every day, every week, and every month.
It’s relatively easy to echo metrics to one dashboard or report. The single point of measurement lets you deliver a URL or a shared email with a consistent result. What happens when you need a key metric to be available across the organization?
A team member wants to count the number of sales-qualified leads from a start date to an end date and compare that number to another value during the same date range. Another person wants to measure a historical value to see how marketing conversion results compared across sources.
How do you help them to count the same way even if you’re not creating the query?
Monolith vs. Microservice
There are two obvious data designs to address this issue, balancing the difficulty to implement for an operations team and the flexibility and performance of the solution.
A monolithic dataset
If you only have one data set, it’s easier to aggregate metrics and provide the same answer to everyone who creates a query, correct? Sort of. While creating a single data set makes it possible to calculate many different kinds of results from the same data it also doesn’t demonstrate how to create results.
When you aggregate results, it’s important to filter the same way to create consistent metrics. For example, if you want the number of sales-qualified leads during a period as suggested above, you also need to know what fields indicate qualification. Is it simply the presence of the SQL date or is there another way you would know? (Yes, I know that dataset design plays a role here in making metrics easily understandable.)
Microservices or fact tables that answer questions
Another way to handle metrics delivery is to provide pre-computed information in tables by date range (a daily, weekly, monthly, or quarterly count). You could also present this information as a microservice to call an internal URL with a metric name and date range and get a result.
The problem with these fact tables? They are limited in scope and don’t answer other, more speculative questions. Suppose you need to cut the data according to a different time grain or want a related series with related data. You will still need someone with data smarts to help you link the information together and validate the result.
Building a semantic layer
One potential solution? Make common metrics available to be incorporated into other data sets, but compute them on a known schedule and time grain so they can be used easily in a business intelligence tool or a report.
This layer presents a simplified view of organizational metrics without sharing the complexity that goes into their definition. It also makes it possible for non-technical users to add metrics to their reports while ensuring they are sharing accurate information.
Having one place to go to find “Daily SQLs” or “Current MRR” or “Monthly customer count” makes it a lot more reliable to use those metrics in other reports and to believe they are the most accurate numbers. In addition, if the definition for this metric changes, it’s possible to annotate this metric or create a new parallel piece of information that supports the needs of the business.
Where to exercise caution
Building a semantic layer for your business doesn’t remove the need to think about the most important metrics to explain the business. It does give you fewer places to search and more certainty when the information changes.
There are a few things to remember about semantic data layers:
-
This technique does not answer every data question; it makes it easier and more effective to answer the most common data questions.
-
If team members go around this definition and create their own, inconsistent analysis is possible.
-
It’s tempting to take aggregated metrics like a weekly count and using these to fit other time grains. Make sure you go larger (daily data aggregated into weekly counts) instead of smaller.
How should you get started? Identify something you count every day and you’ll begin building the catalog of metrics that ought to have this treatment. Learn how they fit together and ask people who consume this data how they think it’s calculated. You might also find the shared definition of a metric is different from the actual definition, and when you do it’s a good way to align the organization.
What’s the takeaway? Finding the right (and frequently updated) metrics for your org is easier when you centralize on a dataset or make it easy to find fully computed metrics in expected time grains. By making aggregated metrics available in a consumable format, you lower the risk of users creating their own and using different definitions than the standard metric.